
Longitudinal data, or data collected multiple times from the same cases, are increasingly popular. They come in many shapes and sizes, from traditional panel surveys to social media data, administrative data or sensor data. One of the great strengths of this type of data is its ability to facilitate causal analysis. While it does not “prove causality”, by understanding the causal order of events we can get one step closer to understanding the underlining processes involved in the social world.
This type of data can also help answer one particular type of question that appears in many fields: what is the causal direction of variables? For example, we might know that mental health and physical health are related but we might not be sure which is the cause and which the effect. We may have plausible theoretical mechanisms in both directions. For example, a decrease in physical health can lead to anxiety, depression and outcomes associated with mental health. We can also think of an opposite process where a sudden decrease in mental health can lead to lower physical health due to a decrease in physical activity.
Longitudinal data can be used to disentangle such processes. One of the model developed explicitly to investigate such questions is the cross-lagged model. This model uses the Structural Equation Modelling (SEM) framework to estimate the two processes concurrently while controlling for possible confounders. In this blog-post we will walk through how to apply this method using R and how you can formally test the causal direction of two variables.
The cross-lagged model
We can use the SEM visualization framework to understand this model. In this framework observed variables are represented by squares, regression coefficients by single headed arrows, correlations by double headed arrows and residuals by small circles.
Given this notation, we can represent the cross-lagged model using such a graph:
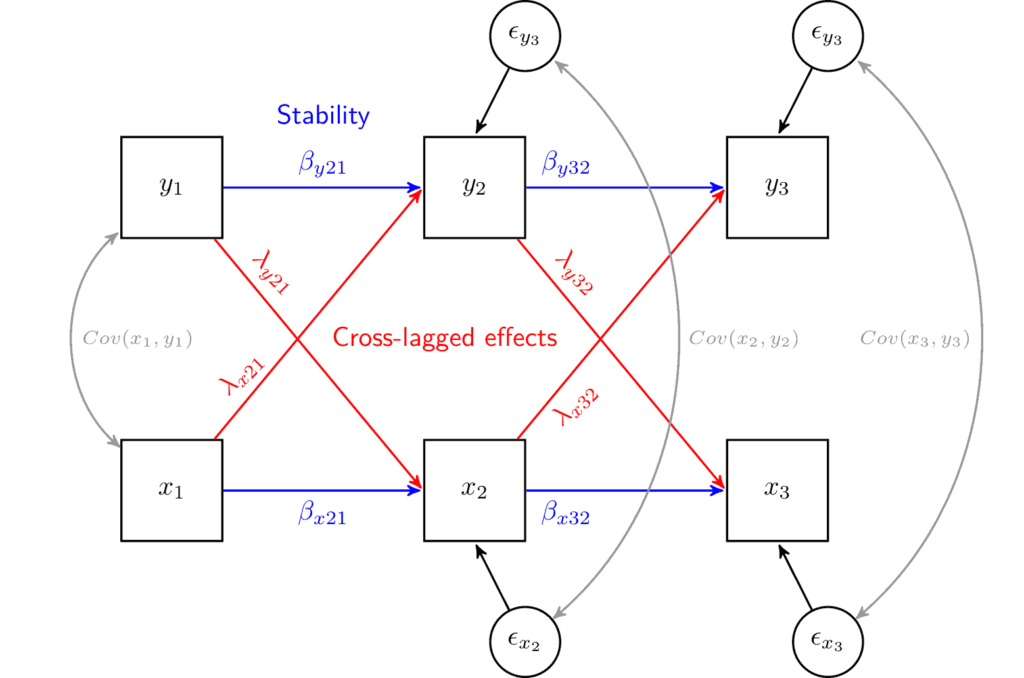
Here we have two variables of interest x and y. They are each measured at three points in time (e.g., x1, x2, x3). The model has three different parts:
- Cross-lagged effects capture the impact of one variable at a previous wave on the current values of another. For example, λy21 (lambda) represents the effect of y in wave 1 on x in wave 2. The opposite effect, λx21, represents the effect of x in wave 1 on y in wave 2. By comparing these two coefficients we can understand if the effects in one direction are stronger than the effects in the other. This comparison is at the heart of this model and informs us about the causal direction.
- Stability coefficients capture how stable each variable is. It is estimated by including auto-regressive coefficients in which the values at the previous wave are influencing the values at the current wave. For example, coefficient βy21 (beta) captures the stability of y1 on y2. If y would represent something like mental health we would interpret it as the stability of mental health from wave 1 to wave 2. The closer the value is to 1 the more stable the variable (i.e., cases don’t change their rank order on mental health). If the coefficient is close to 0 it means that the previous values do not effect the current status while if it is -1 it means that the order of the individuals on that variable reversed. Typically, in this model we are not really interested in this type of coefficient but we treat it as a control. We are effectively controlling for previous levels of x and y, which, in turn, makes the assumption of controlling for possible confounders more plausible. These coefficients are also known as lag-1 effects or a Markov chain as the model implies that only the prior wave information is important for the current status.
- Time-specific correlations capture the correlation between the two variables of interest at each point in time. This is also used as a control to take account of possible time specific confounders that might impact both variables. For example, maybe there is a global pandemic during the data collection at the second time point which leads to a decrease in both x and y. These correlations would capture this process and would control for it.
We can also represent the model using a set of formulas. These represent the same model as above. The β coefficients represent the stability and the λ represents the cross-lagged effects. The ϵ (epsilon) are the regression residual coefficients (or unexplained variance) for each dependent variable. The ν (nu) represents the intercept, or the expected value of the outcome when the predictors are 0. Lastly, we have the correlation between x and y at each wave (j).
xj = νxj + βx, j, j − 1xj − 1 + λy, j, j − 1yj − 1 + ϵxj
yj = νyj + βy, j, j − 1yj − 1 + λx, j, j − 1xj − 1 + ϵyj
Cov(xj,yj)
Running the cross-lagged model in R
Now that we have an idea about why we would use the cross-lagged model and what are the main components we can see how to estimate it in R. Here we will use data from the first three waves of the Understanding Society Survey. Our research question focuses on the causal direction of mental health (“mcsc”) and physical health (“pcsc”). These are calculated scores based on the SF12 scale. The values go from 0 to 100 where higher number = better health.
Here we centered the variables to make them easier to interpret. That is done by subtracting the average from each variable so the new mean is 0. This does not change regression coefficients but does make intercepts easier to interpret.
To run the model we use the lavaan package.
library(lavaan)
We split the process in three steps. First, we write the model as a simple text object and save it as “model”:
model <- 'pcsc_2 ~ 1 + pcsc_1 + mcsc_1
pcsc_3 ~ 1 + pcsc_2 + mcsc_2
mcsc_2 ~ 1 + mcsc_1 + pcsc_1
mcsc_3 ~ 1 + mcsc_2 + pcsc_2
pcsc_1 ~~ mcsc_1
pcsc_2 ~~ mcsc_2
pcsc_3 ~~ mcsc_3'We see that we have four regression models, represented by the “~” symbol. On the left of the symbol we have the dependent variable or outcome. One the right side we have the predictors, or independent variables. For example, the first line says that we want to explain physical health in wave 2 (“pcsc_2”) by physical health in wave 1 (“pcsc_1”, this represents stability) and mental health in wave 1 (“mcsc_1”, this represents the cross-lagged effect). The “1” value in the regression represents the intercept. We also include correlations between variables at each wave, represented by “~~”.
Note that lavaan figures out on its own if the correlation is between the observed variables or the residuals.
Now that we have the model we can estimate it using the sem() command. We give it as inputs the model, the data (“usw” stand for Understanding Society in wide format). We also add an option to estimate the model using Full Information Maximum Likelihood (missing = "ML"). This uses all the available information to estimate the model and leads to fewer missing cases in the model than listwise deletion (which is the default).
m1 <- sem(model, data = usw, missing = "ML")
Now that we have the model stored as “m1” we can print the results using the summary() command. We also ask for the standardized coefficients using the standardized = TRUE option.
summary(m1, standardized = TRUE) ## lavaan 0.6-12 ended normally after 93 iterations ## ## Estimator ML ## Optimization method NLMINB ## Number of model parameters 23 ## ## Used Total ## Number of observations 26673 27189 ## Number of missing patterns 7 ## ## Model Test User Model: ## ## Test statistic 3071.548 ## Degrees of freedom 4 ## P-value (Chi-square) 0.000 ## ## Parameter Estimates: ## ## Standard errors Standard ## Information Observed ## Observed information based on Hessian ## ## Regressions: ## Estimate Std.Err z-value P(>|z|) Std.lv Std.all ## pcsc_2 ~ ## pcsc_1 0.764 0.005 163.893 0.000 0.764 0.744 ## mcsc_1 0.138 0.005 26.102 0.000 0.138 0.118 ## pcsc_3 ~ ## pcsc_2 0.739 0.004 167.272 0.000 0.739 0.757 ## mcsc_2 0.121 0.005 22.807 0.000 0.121 0.104 ## mcsc_2 ~ ## mcsc_1 0.526 0.006 92.685 0.000 0.526 0.537 ## pcsc_1 0.110 0.005 21.995 0.000 0.110 0.128 ## mcsc_3 ~ ## mcsc_2 0.586 0.006 103.097 0.000 0.586 0.578 ## pcsc_2 0.081 0.005 16.663 0.000 0.081 0.095 ## ## Covariances: ## Estimate Std.Err z-value P(>|z|) Std.lv Std.all ## pcsc_1 ~~ ## mcsc_1 -1.748 0.679 -2.573 0.010 -1.748 -0.016 ## .pcsc_2 ~~ ## .mcsc_2 -14.337 0.428 -33.464 0.000 -14.337 -0.236 ## .pcsc_3 ~~ ## .mcsc_3 -16.172 0.405 -39.897 0.000 -16.172 -0.285 ## ## Intercepts: ## Estimate Std.Err z-value P(>|z|) Std.lv Std.all ## .pcsc_2 -0.441 0.051 -8.671 0.000 -0.441 -0.038 ## .pcsc_3 -0.010 0.049 -0.210 0.834 -0.010 -0.001 ## .mcsc_2 -0.253 0.054 -4.661 0.000 -0.253 -0.026 ## .mcsc_3 0.086 0.053 1.616 0.106 0.086 0.009 ## pcsc_1 0.012 0.069 0.170 0.865 0.012 0.001 ## mcsc_1 0.007 0.061 0.121 0.904 0.007 0.001 ## ## Variances: ## Estimate Std.Err z-value P(>|z|) Std.lv Std.all ## .pcsc_2 57.309 0.553 103.694 0.000 57.309 0.435 ## .pcsc_3 51.907 0.506 102.527 0.000 51.907 0.413 ## .mcsc_2 64.624 0.629 102.727 0.000 64.624 0.698 ## .mcsc_3 62.145 0.602 103.201 0.000 62.145 0.654 ## pcsc_1 124.936 1.091 114.466 0.000 124.936 1.000 ## mcsc_1 96.520 0.845 114.214 0.000 96.520 1.000
The coefficients of interest are under the “Regressions” section of the output. There, the first row gives us the effect of physical health in wave 1 (“pcsc_1”) on physical health in wave 2 (“pcsc_2”). This can be interpreted like any regression coefficient. If physical health in wave 1 is higher by one point, then the expected value of physical health in wave 2 would be higher by 0.764. This relationship is quite strong. This implies that physical health is relatively stable in time. By comparison the stability of mental health is somewhat lower at 0.526.
The next row in the output presents the first cross-lagged coefficient. It indicates that an increase in mental health in wave 1 by one point would lead to an increase of physical health in wave 2 of 0.138. We can compare this with the opposite cross-lagged effect, physical health in wave 1 on mental health in wave 2. Based on the results, the coefficient for this relationship is 0.110. If we look at the cross-lagged effects of wave 2 on wave 3 we see that the effect of mental health on physical health is 0.121 while the other way it is
0.081.
To help with the interpretation of this model I recommendo draw the model and to add the observed coefficients in the appropriate place. For example, if we take the coefficients from the output and put them in the SEM figure we would get:
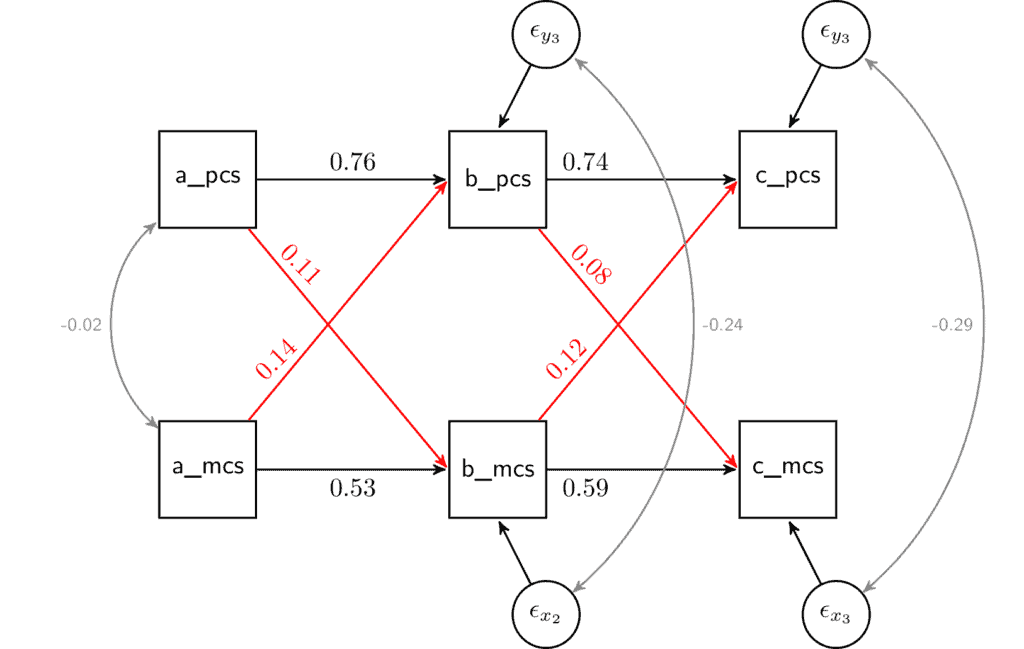
The graph makes it a little clearer that there is a relationship between mental and physical health. And, while the effect of mental health on physical health is slightly larger the difference is relatively small. Next, we can do a formal test to see if the two coefficients are significantly different from each other.
Note that here the two variables use the same scale and we can compare them using the un-standardized coefficients. When the variables have different scales either re-scale them or interpret the standardized coefficients (the last column in the output “Std.all”).
Testing the equality of cross-lagged coefficients
The SEM framework offers some useful tools for explicitly testing the equality of coefficients. The typical procedure for this is to run a model without constraints (like the one we ran above) and then run a model with some constraints. These can be added by fixing a coefficient to a particular value (e.g., saying a regression coefficient is 0) or by forcing some coefficients to be equal.
Our research question focuses on the equality of the cross-lagged effects. We want to formally test if the effect of mental health on physical health is significantly different to the reverse relationship. The way to add such a restriction is by giving the two coefficients the same “name”. Below is a visual representation where we show how we would restrict the cross-lagged effects from wave 1 to wave 2 to be called “a” while those from wave 2 to wave 3 to be called “b”.
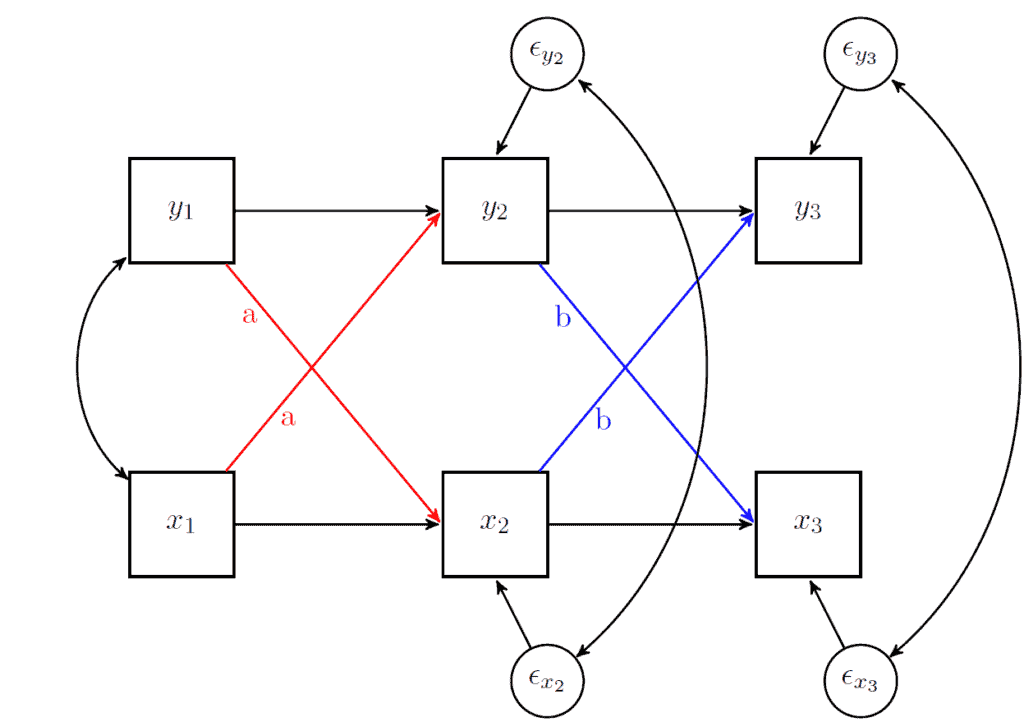
In general, I recommend to do this in stages. So, here we will test if the cross-lagged coefficients from wave 1 to wave 2 are equal. This would test if 0.138 is equal to 0.110 in the population. If the model with the restriction is significantly worse we could say that the mental health on physical health (0.138) has a larger effect than the other way around (0.110).
To add a name or a restriction in lavaan we simply put the value in front of the coefficient with a “*” next to it. The code below fixes the cross-lagged coefficients from wave 1 to wave 2 to be called “a” (thus making them equal).
model <- 'pcsc_2 ~ 1 + pcsc_1 + a*mcsc_1
pcsc_3 ~ 1 + pcsc_2 + mcsc_2
mcsc_2 ~ 1 + mcsc_1 + a*pcsc_1
mcsc_3 ~ 1 + mcsc_2 + pcsc_2
pcsc_1 ~~ mcsc_1
pcsc_2 ~~ mcsc_2
pcsc_3 ~~ mcsc_3'
m2 <- sem(model, data = usw, missing = "ML")
summary(m2, standardized = TRUE)
## lavaan 0.6-12 ended normally after 93 iterations
##
## Estimator ML
## Optimization method NLMINB
## Number of model parameters 23
## Number of equality constraints 1
##
## Used Total
## Number of observations 26673 27189
## Number of missing patterns 7
##
## Model Test User Model:
##
## Test statistic 3086.156
## Degrees of freedom 5
## P-value (Chi-square) 0.000
##
## Parameter Estimates:
##
## Standard errors Standard
## Information Observed
## Observed information based on Hessian
##
## Regressions:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## pcsc_2 ~
## pcsc_1 0.761 0.005 166.372 0.000 0.761 0.744
## mcsc_1 (a) 0.124 0.004 34.159 0.000 0.124 0.106
## pcsc_3 ~
## pcsc_2 0.739 0.004 167.338 0.000 0.739 0.755
## mcsc_2 0.122 0.005 23.094 0.000 0.122 0.105
## mcsc_2 ~
## mcsc_1 0.530 0.006 95.512 0.000 0.530 0.539
## pcsc_1 (a) 0.124 0.004 34.159 0.000 0.124 0.143
## mcsc_3 ~
## mcsc_2 0.585 0.006 103.102 0.000 0.585 0.580
## pcsc_2 0.080 0.005 16.440 0.000 0.080 0.094
##
## Covariances:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## pcsc_1 ~~
## mcsc_1 -1.752 0.679 -2.578 0.010 -1.752 -0.016
## .pcsc_2 ~~
## .mcsc_2 -14.346 0.429 -33.467 0.000 -14.346 -0.236
## .pcsc_3 ~~
## .mcsc_3 -16.169 0.405 -39.891 0.000 -16.169 -0.285
##
## Intercepts:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## .pcsc_2 -0.435 0.051 -8.572 0.000 -0.435 -0.038
## .pcsc_3 -0.012 0.049 -0.246 0.806 -0.012 -0.001
## .mcsc_2 -0.260 0.054 -4.787 0.000 -0.260 -0.027
## .mcsc_3 0.087 0.053 1.652 0.099 0.087 0.009
## pcsc_1 0.012 0.069 0.172 0.864 0.012 0.001
## mcsc_1 0.007 0.061 0.119 0.905 0.007 0.001
##
## Variances:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## .pcsc_2 57.329 0.553 103.684 0.000 57.329 0.438
## .pcsc_3 51.903 0.506 102.528 0.000 51.903 0.414
## .mcsc_2 64.649 0.629 102.702 0.000 64.649 0.692
## .mcsc_3 62.145 0.602 103.201 0.000 62.145 0.652
## pcsc_1 124.942 1.092 114.466 0.000 124.942 1.000
## mcsc_1 96.516 0.845 114.217 0.000 96.516 1.000If we look at the results we see that the two coefficients named “a” have the same value: 0.124. Now that we have this more restrictive model we can compare it with the previous one to see if it’s “significantly” worse.
There are different ways to compare models in SEM. A quick way to do it is to use the anova() command with the two models we estimated. This will create a small table with the AIC, BIC and the Chi square test for the difference:
anova(m1, m2) ## Chi-Squared Difference Test ## ## Df AIC BIC Chisq Chisq diff Df diff Pr(>Chisq) ## m1 4 1009341 1009529 3071.5 ## m2 5 1009353 1009533 3086.2 14.608 1 0.0001323 *** ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
AIC and BIC are relative fit indices. They do not have a fixed scale but lower values are better. Based on these two indicators “m1” is better. We can also use the Chi square difference test (also sometimes represented as: Δχ2). This takes the difference of the Chi square and the degrees of freedom of the two models. The null hypothesis is that the models have equal fit. Here the test is statistical significant. This implies that the model with the restriction (“m2”) is significantly worse than the first model. As a result, we should select “m1”.
All of these fit indices imply that “m1” is preferred, which means that the difference between the two cross-lagged coefficients is significant (i.e., we expect that 0.138 is significantly larger than 0.110 in the population). From a substantive point of view this means that the effect of mental health on physical health is significantly higher than the other way around.
At this point I would urge some caution when interpreting these fit comparisons. Both cross-lagged coefficients are significant. Therefore, we can say that they both influence each-other. In addition, while the difference between the coefficients is statistically significant you should also consider if the difference is substantively important. Consider that the difference between the two coefficients is of 0.028 (0.138 – 0.110). This may or not be a important difference, depending on the topic under research. As such, always remember to contextualize the findings, consider what the coefficients mean from a substantive point of view and think if they are important given the literature and theory.
Conclusions
We saw how we can use longitudinal data and the cross-lagged model to understand the causal direction of two variables. This model is useful when we have two variables that are related but we are not sure about the causal direction. We saw how we can run the model in R and lavaan and how we can formally test the equality of the coefficients.
The model represents an elegant way to test the causal direction. It also has the advantage of controlling for some possible confounders. This is done by controlling for the values on the variables of interest at the previous wave (i.e., the stability coefficients) and with the time specific correlations. That being said, the model is far from perfect. It is still possible to have missing confounders that could bias our estimates (and that we might want to control for). Also, in this form the model does not separate “within” and “between” variation (see this post for a discussion on these two types of variance). That being said the SEM framework is extremely flexible and the model can be extended to deal with these challenges.
For more on longitudinal data analysis check out an introduction to the multilevel model for change and one for the latent growth model.

If that was useful you might also like the Longitudinal Data Analysis Using R book.
This covers everything you need to work with longitudinal data. It introduces the key concepts related to longitudinal data, the basics of R and regression. It also shows using real data how to prepare, explore and visualize longitudinal data. In addition, it discusses in depth popular statistical models such as the multilevel model for change, the latent growth model and the cross-lagged model.
More blog posts
 Interview for Frontmatter podcast discussing survey research and longitudinal data analysis
Interview for Frontmatter podcast discussing survey research and longitudinal data analysis Explaining change in time using multilevel models and time constant predictors
Explaining change in time using multilevel models and time constant predictors Estimating non-linear change in time using the multilevel model for change
Estimating non-linear change in time using the multilevel model for change Summer schools in applied statistics and survey methodology 2023
Summer schools in applied statistics and survey methodology 2023 Estimating change in time. Comparing the multilevel model for change with the Latent Growth Model
Estimating change in time. Comparing the multilevel model for change with the Latent Growth Model Estimating non-linear change with Latent Growth Models in R
Estimating non-linear change with Latent Growth Models in R
Pingback: Data structures for longitudinal analysis: wide versus long - Alexandru Cernat
Pingback: Data structures for longitudinal analysis: wide versus long - Longitudinal data analysis